Build Real Time Streaming Pipeline with Kinesis, Apache Flink and Apache Hudi with Hands-on

Building a real-time streaming pipeline with Apache Hudi, Kinesis, Flink, and S3 involves several steps. Here’s a high-level overview of how you can set it up:
Apache Hudi: Apache Hudi is used for managing large analytical datasets over cloud storage. It provides record-level insert, update, and delete capabilities on data stored in cloud storage systems like S3. You can use Hudi to maintain real-time data and perform incremental data processing.
Amazon Kinesis: Amazon Kinesis is a platform on AWS for collecting, processing, and analyzing real-time, streaming data. You can use Kinesis Data Streams to ingest data, and Kinesis Data Analytics or Kinesis Data Firehose for processing and loading data into other services.
Apache Flink: Apache Flink is a distributed stream processing framework for high-throughput, low-latency, and exactly-once stream processing. Flink can be used to process data from Kinesis Data Streams in real-time, perform transformations, and write the output to other systems like Hudi or S3.
Amazon S3: Amazon S3 is an object storage service that offers scalability, data availability, security, and performance. It can be used as a data sink to store the processed data from the streaming pipeline.
Here’s how you can set up the streaming pipeline:
Data Ingestion:
Use Amazon Kinesis Data Streams to ingest real-time data from your data sources. Configure the data streams and set up producers to send data to the streams.
Let’s create a Kinesis Data Stream.


For the demonstration purpose we are using provisioned capacity mode with 1 shard and rest keep the default configuration and create data stream.

Once the Kinesis Data Stream is Created now let’s ingest the randomly generated data from local system using the faker and boto3 library.
import datetime
import json
import random
import boto3
import os
import uuid
import time
from faker import Faker
faker = Faker()
def getReferrer():
data = {}
now = datetime.datetime.now()
str_now = now.isoformat()
data['uuid'] = str(uuid.uuid4())
data['event_time'] = str_now
data['ticker'] = random.choice(['AAPL', 'AMZN', 'MSFT', 'INTC', 'TBV'])
price = random.random() * 100
data['price'] = round(price, 2)
return data
kinesis_client = boto3.client('kinesis',
region_name='us-east-1',
aws_access_key_id="xxxxx....",
aws_secret_access_key="xxxxx...."
)
while True:
data = json.dumps(getReferrer())
res = kinesis_client.put_record(
StreamName="input-stream",
Data=data,
PartitionKey="1")
print(data, " " , res)The Above code generated some random data and push to Kinesis Data Stream.
Data Processing:
Set up an Apache Flink application to consume data from Kinesis Data Streams.
Write Flink transformations to process the incoming data streams. These transformations could include filtering, aggregating, enriching, or any other data manipulation required for your use case.
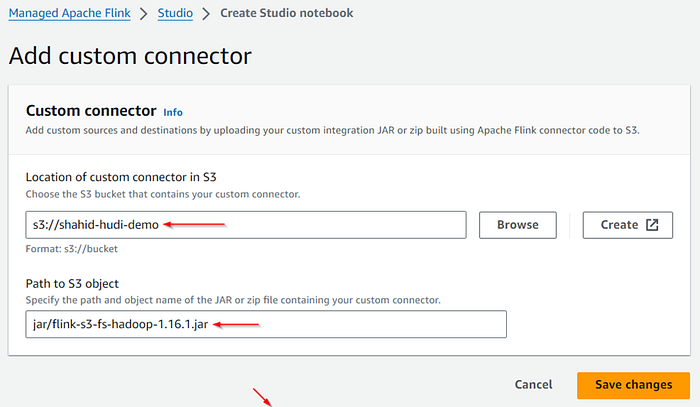
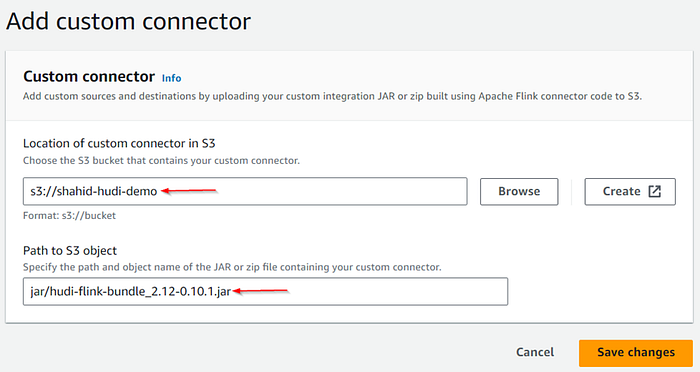
To stream the data from Kinesis to Flink, Hudi and then S3 we required connectors. You can download the connectors from the below links.
Place the downloaded connectors in S3 bucket and copy the path of these jar files.
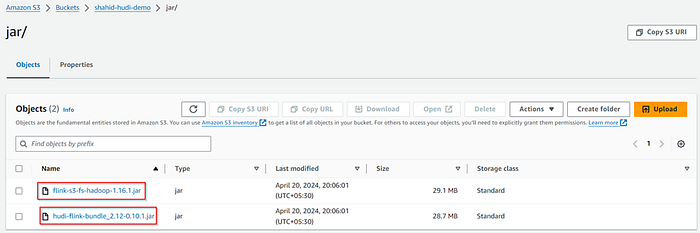
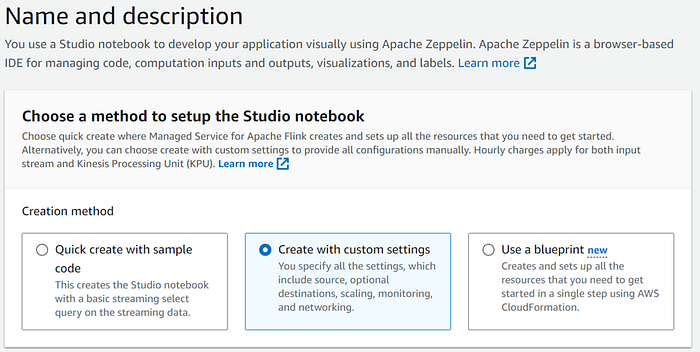
Let’s use the Managed Apache Flink to create notebook and run interactive queries.


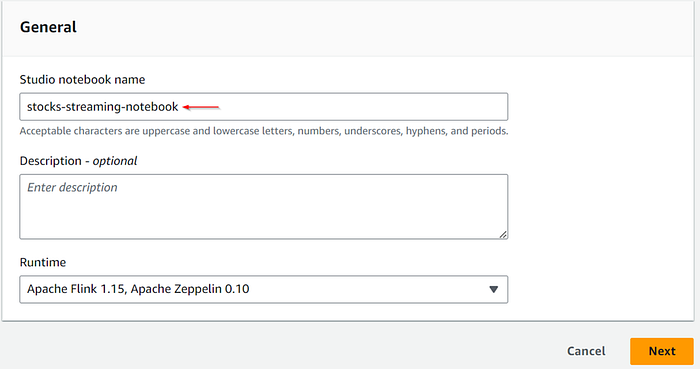
Let’s create a notebook with custom settings and connectors.
We required a database to store the table metadata, hence create new database and table or use existing table. In my case I am using existing table called stocks.
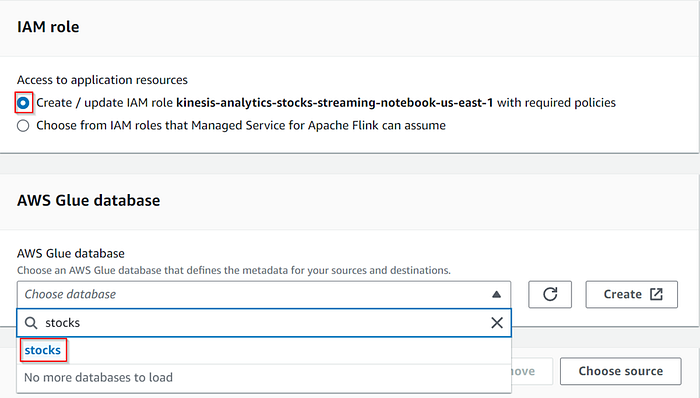
Add the downloaded connectors to the notebook by specifying the S3 path of the JAR files.
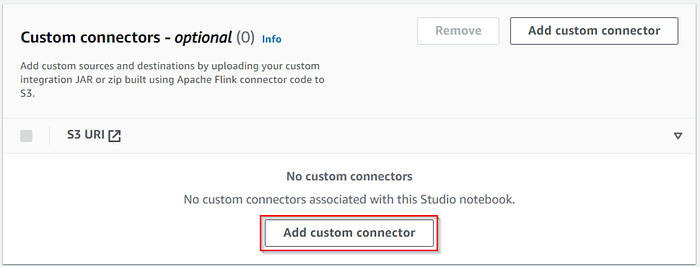
Once you add the connectors, you can view the connects in the custom connectors section.
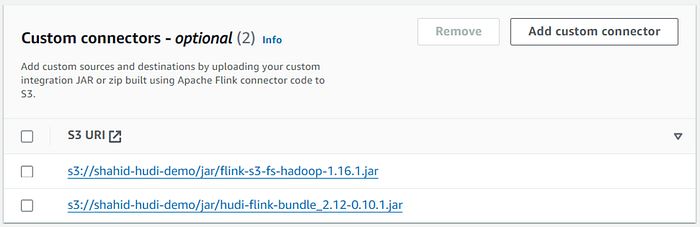
After adding the connectors keep the remaining configuration default and create notebook.
To add the read the streaming data from Kinesis data stream and store it in S3 bucket we need to attach the AmazonS3FullAccess and AmazonKinesisFullAccess to notebook IAM role.
Note: For the demonstration purpose I have given the full access, kindly provide least privilege access
Click on the Notebook IAM role and attach the policy.
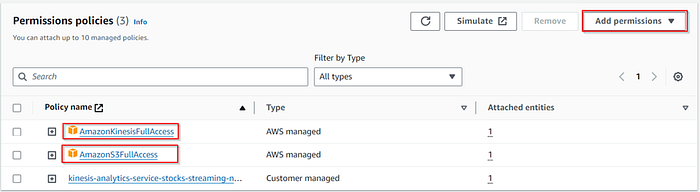
Click on the Add permissions and attach AmazonS3FullAccess and AmazonKinesisFullAccess policy.
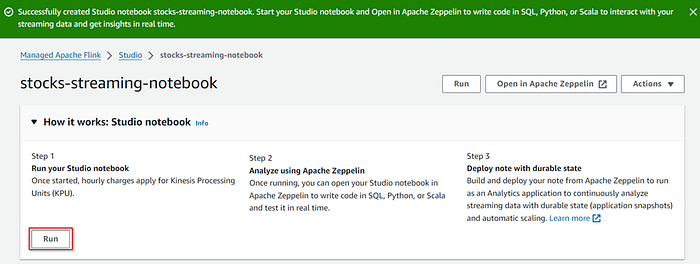
After adding the policy to notebook IAM role then go back to notebook and click on Run button in order start the notebook.
It takes a while to create a notebook, once you see the status of the notebook running then launch the notebook by clicking the open in Apache Zeppelin button.
Create new notebook and provide the name for it.
In a Zeppelin notebook, the %flink.conf command is used to set Flink configuration properties for the Flink interpreter in Zeppelin.
The specific configuration property execution.checkpointing.interval is setting the interval for checkpointing in milliseconds. Checkpointing is a crucial feature in fault-tolerant stream processing systems like Apache Flink. It enables the system to take snapshots of the state of the processing application periodically, allowing it to recover from failures and ensure fault tolerance.
Run the Below code to set the checkpoint interval to 5 seconds.
In this case, execution.checkpointing.interval 5000 sets the checkpointing interval to 5000 milliseconds, meaning that Flink will take a checkpoint of the application’s state every 5 seconds.

Create a stock_table which is used to read the data from the Kinesis data stream and partition it by ticket field.

Data Storage:
Use Apache Hudi to manage your analytical datasets on Amazon S3. Configure Hudi tables to store the processed data in an incremental manner, allowing for efficient updates and deletes.
Alternatively, if you prefer to store raw data or processed data in a different format, you can directly write the output of your Flink application to Amazon S3.
Create a table stock_table_hudi which acts like a sink/destination where it reads the data from stock_table and pass to Hudi which stored it in S3 bucket.

Run the SQL Command to insert the data from stock_table to stock_table_hudi which stored the data in S3.

The above command will run continuously and push the data to Hudi which in turn store in it S3 bucket.
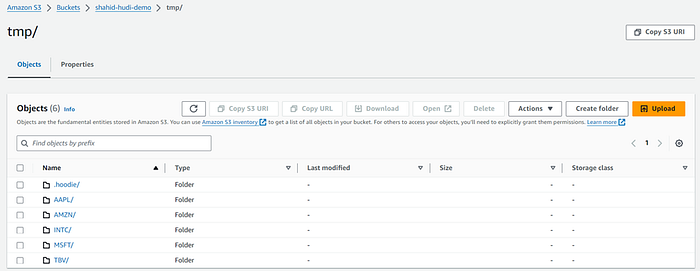
In the below Image you can see the data has been stored in provided S3 bucket tmp folder with partitions.
Deployment and Monitoring:
Deploy and configure your Flink application to run on a cluster of machines, either on-premises or on a cloud platform like AWS.
Set up monitoring and alerting to track the health and performance of your streaming pipeline. Tools like Amazon CloudWatch can be used for monitoring various metrics.
Additional Considerations:
Ensure proper security and access control for your data and resources.
Implement fault tolerance and resilience in your streaming pipeline to handle failures gracefully.
Tune the performance of your Flink application and infrastructure to meet your throughput and latency requirements.
By integrating Apache Hudi, Kinesis, Flink, and S3, you can build a robust and scalable real-time streaming pipeline for processing and analyzing streaming data.
Conclusion:
In conclusion, integrating Apache Hudi, Kinesis, Flink, and S3 enables the creation of a robust real-time streaming pipeline. This architecture provides reliable data ingestion, efficient stream processing, and scalable storage, empowering organizations to derive insights and make informed decisions from streaming data in real-time.
Github link: https://github.com/MdShahidAfridiP/Real-Time-Streaming-Pipeline-with-Kinesis-Apache-Flink-and-Apache-Hudi

