Building a Streaming Data Pipeline With Kafka And Spark
Learning Big Data may be easy, applying the knowledge not so much. That’s why in this tutorial I will show you how to build and end-to-end real-time data pipeline.
Before we start
In this tutorial I will cover how to create a data streaming pipeline, but I will not do a deep dive in each technology. So, if you are not quite familiar with Spark, Kafka and no-relational databases I recommend you to take a look at those topics before starting this data stream pipeline.
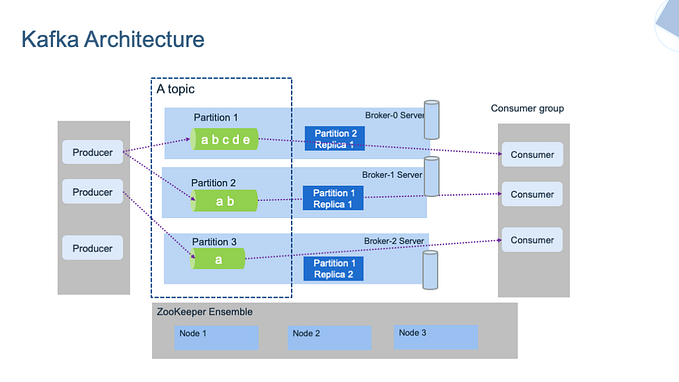
Let’s get started… the architecture
Data pipelines in real world environments can get really complicated and with tons of technologies that may confuse you. In this tutorial, I will cover the basis logic of a streaming data pipeline. I will use a Spotify playlist as source data, Kafka as ingestion tool, Spark SQL for data processing, and MongoDB to store the processed data.
The logic is simple, but functional and scalable. Let’s do a quick review of each technology used in our pipeline and its purpose.
Spotify: It’s a digital music streaming service. It gives you instant access to an online library of music and podcasts, allowing you to listen to any content of your choice at any time. It is both legal and easy to use. In this…