Elasticsearch — solution to searching
An enterprise-grade Search and Analytics engine
Elasticsearch is a full-text search engine for our own data. It indexes our data and makes it searchable via an HTTP interface. It is a Lucene-based distributed search engine. It can scale to petabytes of data. It supports multi-tenancy and high concurrency. It delivers search results in near real-time. Elasticsearch is also one component of a set of open-source tools known as the ELK Stack.
Use cases of Elasticsearch
- Operational Logging and Log Analysis (ELK)
- Site content & media search
- Full-Text Search
- Event Data and Metrics
- Visualizing Data with Kibana
Cluster

An Elasticsearch cluster is a distributed collection of nodes that each perform one or more cluster operations. Each node runs an instance of ES application. The cluster is horizontally scalable. By adding additional nodes to the cluster we can scale the cluster capacity linearly while maintaining similar performance. Nodes are added by creating and using an enrollment token.
Nodes in the cluster can be differentiated based on the specific type of operations that they perform. In Highly available clusters, we designate different sets of nodes for different cluster functions. To define node roles we can set the configuration like this — node.roles: [ master | data | ingest ]
Master Node
Each cluster has a single master node at any point in time and its responsibilities include maintaining the health and state of the cluster. Master nodes function as a coordinator for creating, deleting, managing indices, and allocating indices and the underlying shards to the appropriate nodes in the cluster.
Master Eligible Node
Master-eligible nodes are the ones that are candidates for being master node.
Data Node
Data nodes hold the actual index data and handle the search and aggregation of data.
Coordinator only Node
These nodes broadcast query requests to all relevant shards and aggregate their responses into a globally sorted set, which is returned to the client. These nodes act as the load balancer.
Ingesting Node
Ingest nodes can be configured to pre-process data before it gets ingested. As some of the processors such as the grok processor can be resource-intensive, dedicating separate nodes for the ingest pipeline is beneficial as search operations will not be impacted by ingest processing. Otherwise, data nodes will perform this task.
In large cloud clusters, we will have dedicated master node, 2 or more ingesting node, 2 or more coordinating node and multiple data nodes.
Since data nodes store the data they should have attached disks. SSDs for warm data and HDD for cold data. Also we need large memory (RAM) for data nodes as they buffer data.
Elasticsearch is written in Java and runs processes in JVM. It uses thread pools for different process.
GET /_cat/thread_pool/search?v&h=host,name,active,rejected,completed
Index
Index is collection of similar type of documents. It is a logical entiy. Physically it is mapped to shards. Index is assocaited with settings, mapping, aliases, and template.
Index Aliases
An alias is a virtual index name that can point to one or more indices. This removes the need to keep a track of which specific index to query, in case the data is spread across indices.

GET _cat/aliases?v
POST _aliases
{
"actions": [
{
"add": {
"index": "index-1",
"alias": "alias1"
}
}
]
}Index aliases also help in index migration without downtime.
Shards
Indices are split horizontally into pieces called shards. Shards are independent Lucene index. They are the building blocks of index.
Elasticsearch recommends each shard to be under 65GB (AWS recommends them to be under 50GB), so we could create time-based indices where each index holds somewhere between 16–20GB of data, giving some buffer for data growth.
Primary & Replication Shards
To get the shards of an index GET _cat/shards/index
Life cycle of shard: Initializing → Started →Relocating → Unassigned
{
"settings" : {
"index" : {
"number_of_shards" : 8,
"number_of_replicas" : 2
}
}
}Translog / Memory Buffer
Lucene commits are too expensive to perform on every individual change, so each shard copy also writes operations into its transaction log known as the translog. Each shard has one translog. The data in the translog is only persisted onto a disk with Lucene commit. In case of failure, this is replayed to commit the unsaved changes. During a commit, all the segments in memory are merged into a single segment and saved to disk.
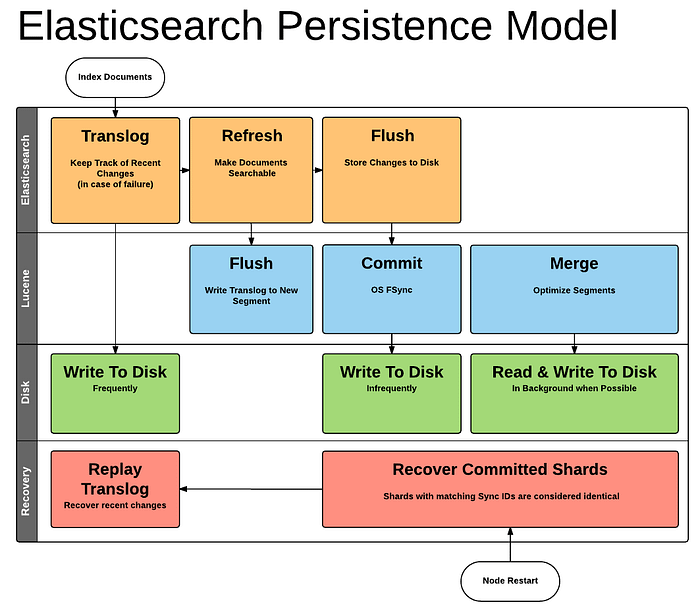
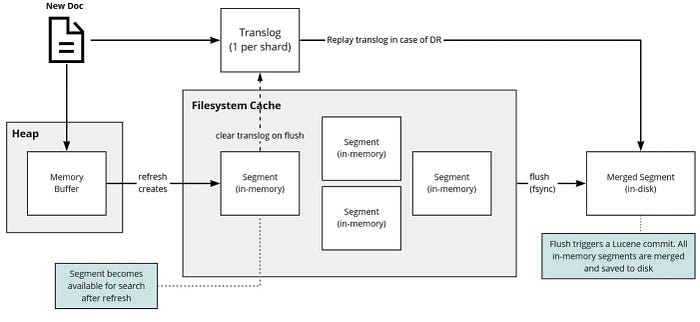
Refresh — memory buffer content is copied to a newly created segment in the memory and translog is cleared. Happens every second.
Flush — In-memory segments are written to disk. Smaller segments are merged into large segments.
Segments
The Lucene index is divided into smaller files called segments. Segments are inverted index. Segments are immutable. Lucene searches in all segments sequentially. So having a lot of segments can impact performance. Elasticsearch merges the segments to create new segments by expunging deleted documents. Merging also helps to combine smaller segments into larger segments as smaller segments have poor search performance.
Documents
A document is a unit of information passed on to Elasticsearch for storage. Documents are JSON files that are stored within an Elasticsearch index and are considered the base unit of storage. Documents are immutable. In case of an update older file is replaced with the new one. The _version field in the doc response is a thing of the past and has no significance now.
Fileds
data types like binary, boolean, keyword, numbers, dates, text, geo_shape, search_as_you_type
Meta fields
_index — name of the index
_type
_id — unique id of the document
_source — original JSON document before applying any analyzers / transformations.
_all — contains every other field in your document
Indicative mapping of ES object with database:
MySQL => Databases => Tables => Row => Column => Index
Elasticsearch => Indices => Types => Documents => Properties => Mapping
Internal data structures used by ES
Inverted Index — For text data
BKD Tree — Numeric, date, Geospatial data
doc_values — sorting & aggregations
Analyzers
Elasticsearch provides analyzers that define how the text should be indexed and searched. Analyzers are used during indexing to parse phrases and expressions into their constituent terms. Defined within an index, an analyzer consists of a single tokenizer and any number of token filters.
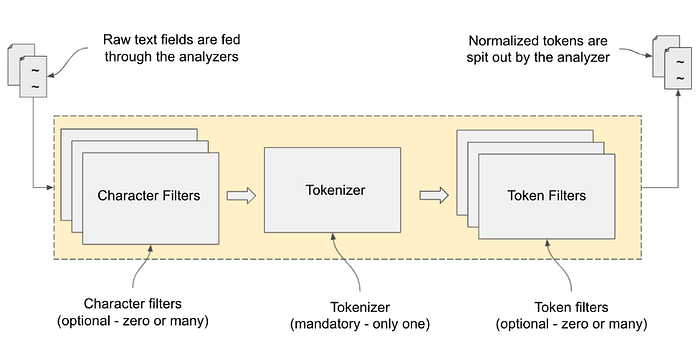
The analyzer has three components:
- Character Filters
(html_strip) - Tokenizer
(standard) - Token Filter
(lowercase)
Elasticsearch has a lot of built-in analyzers, tokenizers, and token filters.
POST /_analyze
{
"text": "This text will be analyzed with STANDARD analyzer"
"analyzer": "standard"
}
POST /_analyze
{
"text": "This text will be analyzed with STANDARD analyzer"
"char_filter": [],
"tokenizer": "standard",
"filter": [ "lowercase" ]
}Index Template
An Index template is a skeleton using which a new index is created.
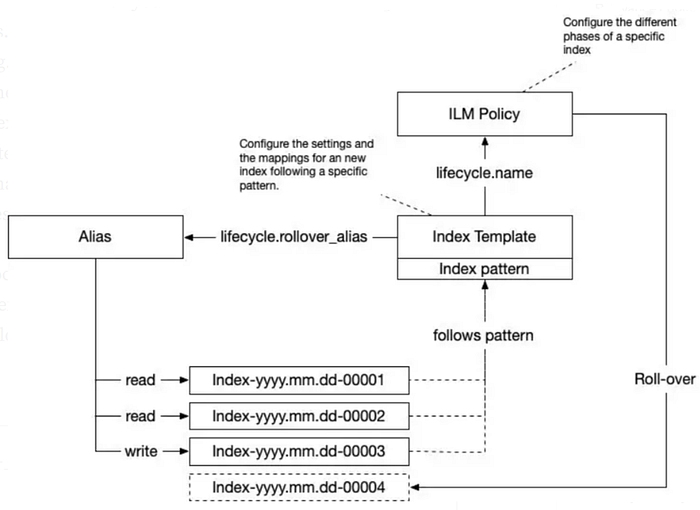
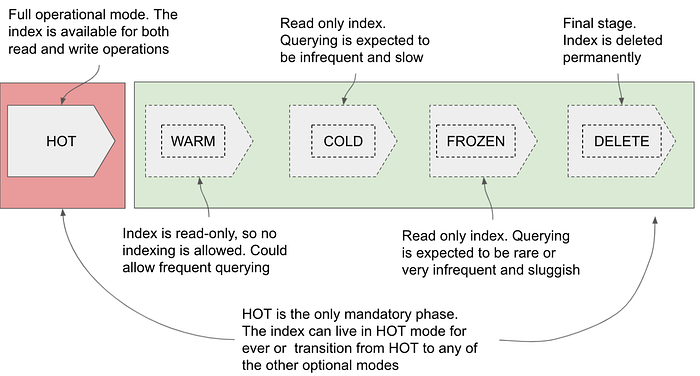
Index Lifecycle Management
Each index goes through different phases (hot → warm →cold → deleted). Based on a pre-defined configuration ILM will mode indices from one phase to another.
Ingest Pipeline
Ingest pipelines allow us to apply transformations such as field deletions, info extraction, or even data enrichment prior to indexing a document. A pipeline consists of several configurable tasks known as processors. Pipelines are stored by Elasticsearch as an internal data structure in the cluster state.
GET _nodes/ingest?filter_path=nodes.*.ingest.processors
PUT _ingest/pipeline/blog-demo-pipeline
{
"version": 1,
"description": "Demo pipeline for medium blog",
"processors": [
{
"set": {
"description": "Set default value of Tag",
"field": "StoryTag",
"value": "Data Engineering"
}
},
{
"lowercase": {
"field": "author"
}
},
{
"remove": {
"field": "external_reads"
}
}
]
}
POST _ingest/pipeline/blog-demo-pipeline/_simulate
{
"docs": [
{...}
]
}
POST users/_doc?pipeline=blog-demo-pipeline
{...}
POST _reindex
{
"source": {
"index": "existing index name"
},
"dest": {
"index": "new index name",
"op_type": "create",
"pipeline": "blog-demo-pipeline"
}
}Data Replication
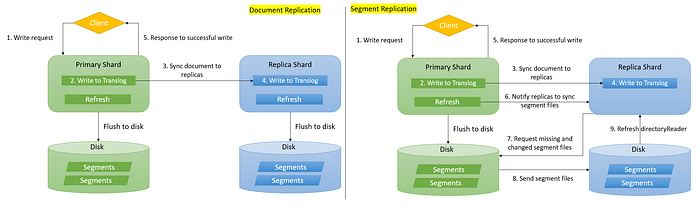
Elasticsearch has concepts of Primary Shard and Replica Shard.
The process of replicating data from Primary to replica shard is called Data Replication. The core consideration of Data Replication is the delay ( Lag ) of Replica and Primary. If Lag is always 0, then it is real-time replication with the highest reliability. Elasticsearch implements Data Replication with the help of Document Replication and Segment Replication.
Document Indexing
Input data to Elasticsearch is analyzed and tokenized before it gets stored. Typically only the analyzed tokens are stored by the Lucene library. Elasticsearch also stores the original document as received in a special field called the _source. Although it consumes additional storage space, _source field is critical in providing document update functionality and is also required for reindex operations.
Document Routing
Elasticsearch uses a routing algorithm to distribute our documents to the underlying shards while indexing. Each of the documents will be indexed in one and only one primary shard. The documents are evenly distributed so there is no chance of one of the shards getting overloaded.
The routing algorithm is a simple formula where Elasticsearch deduces the shard for a document during indexing or searching:
shard = hash(id) % number_of_shardsThe hash function expects a unique id, generally a Document ID, or even a custom ID provided by the user.
Note: Documents are not retrieved from the primary shard but ES leverages Adaptive Replica Selection (ARS) to pick a shard from the replication group.
The flow of Index requests in ES
- The request is received by a coordinating node.
- The node routes docs to their indexes and shards.
- Primary and replica shards write(parallel) the docs into translog.
- Docs are normalized (mapping & Analysis) and stored on an in-memory buffer.
- Indexes are refreshed for them to be searchable.
- Lucene commits new segments on disks.
Document Searching
Query Phase — Coordinating node routes the request to all the shards in the index. The shards, independently, perform search and create a priority queue of the results sorted by relevance score. All the shards return the document IDs of the matched documents and relevant scores to the coordinating node. The coordinating node creates a new priority queue and sorts the results globally. The coordinating node creates a priority queue sorting results from all the shards and returns the top 10 hits.
Fetch Phase — Coordinating nodes then requests the original documents from the shards. The shards enrich the documents and return them to the coordinating node.
Document Scoring — Term Frequency(TF), Inverse Document Frequency(IDF), Norm.relevance_score = TF * IDF. We can attach anindices_boostobject at the same level as the query object. This will increase the precedence of the boosted index. Now ES uses Okapi BM25 algorithm to calculate relevance.
There are multiple types of search query predicates:
Term, Terms
ids
exists
range
wildcard
Prefix
regexp
match_phrasse, multi_match, match_all
fuzzy
synonyms
Filter vs Query Context
Filter Context provides a Yes/No answer on the match against the provided query. Filters are cached by default and they don’t contribute to the relevance score of the document. Query Context, however, shows how well each document matches the query. It makes use of Analyzers to make a decision. The results include a relevance score.
Unless it is a full-text search or a relevance score kind of search Filter Context Search is recommended. Filters are generally faster compared to query.
Pagination approaches
- from / size — The
fromparameter defines the number of items we want to skip from the start. Thesizeparameter is the maximum number of hits to be returned. - _scroll API — this is used to retrieve a large number of results. It resembles cursors in SQL databases. Not recommended for user requests. It should be used in batch mode.
- search_after
- Point-in-time (PIT)
Aggregation
Metrics Aggregating — sum, min, max, avg
Numeric / Non-Numeric Metric Aggregates
Bucket Aggregates — sort query results in group
Pipeline Aggregates — pipe aggregate from one stage to another
Data Stream
Data streams simplify handling time-series data. It handles rollover index alias, and indices, and defines common mappings and settings for the backing indices. It leverages the Index Statement Management (ISM) policies.
Configurations
flush_threshold_size
index_buffer_size
refresh_interval
threadpool.bulk.queue_size
Installation on K8s
helm repo add bitnami https://charts.bitnami.com/bitnami
# helm repo add elastic https://helm.elastic.co
helm install elasticsearch --set master.replicas=3,coordinating.service.type=LoadBalancer bitnami/elasticsearch
kubectl port-forward svc/elasticsearch-master 9200
curl localhost:9200Note: ES uses 9200 for API & Search, 9300 for internode communication.
K8s operators
# Elastic
kubectl create -f https://download.elastic.co/downloads/eck/2.5.0/crds.yaml
kubectl apply -f https://download.elastic.co/downloads/eck/2.5.0/operator.yaml
# opensearch
helm repo add opensearch-operator https://opster.github.io/opensearch-k8s-operator/
helm install opensearch-operator opensearch-operator/opensearch-operatorWorking with python
# pip install elasticsearch
# pip install opensearch-py
from elasticsearch import Elasticsearch
from elasticsearch import helpers
import pandas as pd
df = (
pd.read_csv("wiki_movie_plots_deduped.csv")
.dropna()
.sample(5000, random_state=42)
.reset_index()
)
url = 'http://root:root@localhost:9200'
es = Elasticsearch(url)
# es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
mappings = {
"properties": {
"title": {"type": "text", "analyzer": "english"},
"ethnicity": {"type": "text", "analyzer": "standard"},
"director": {"type": "text", "analyzer": "standard"},
"cast": {"type": "text", "analyzer": "standard"},
"genre": {"type": "text", "analyzer": "standard"},
"plot": {"type": "text", "analyzer": "english"},
"year": {"type": "integer"},
"wiki_page": {"type": "keyword"}
}
}
index_name = "movies"
index_exists = es.indices.exists(index = index_name)
if not index_exists:
es.indices.create(index = index_name, mappings = mapping, ignore=400)
# curl -XGET [http://localhost:9200/retail_store]
docs = []
for i, row in df.iterrows():
doc = {
"title": row["Title"],
"ethnicity": row["Origin/Ethnicity"],
"director": row["Director"],
"cast": row["Cast"],
"genre": row["Genre"],
"plot": row["Plot"],
"year": row["Release Year"],
"wiki_page": row["Wiki Page"]
}
docs.append(doc)
helpers.bulk(es, docs, index=index_name, doc_type='_doc')
query = {
"query" : {
"bool" : {
"must" : {
"match_phrase" : {
"cast" : "jack nicholson",
}
},
"filter": {"bool": {"must_not": {"match_phrase": {"director": "roman polanski"}}}},
}
}
}
results = es.search(index=index_name, body=query, size = 20)
# get all hits
# helpers.scan(client=es, query=query, index=index_name)
es.delete(index = index_name, id = doc_id)
# es.delete_by_query(index = index_name, query = query)
es.indices.put_settings(index=index_name, body={"key": "value"})
es.indices.delete(index='movies')
Settings include index-specific properties like the number of shards, analyzers, etc. Mapping is used to define how documents and their fields are supposed to be stored and indexed. We define the data types for each field or use dynamic mapping for unknown fields.
Note: For the bulk APIs, while working with cURL use the Content-Type: application/x-ndjson
Tiered Indexing
Elasticsearch allows us to have different tiers and hence different hardware profiles for data nodes. We do so by setting the node.role attribute in the elasticsearch.yml configuration file.
Hot — data_hot
Warm — data_warm
Cold — data_cold
Frozen — data_frozen
Basic APIs
POST <index-name>/_search?explain=true
GET <index1>,<index2>,<index3>/_search
GET /_cluster/health
GET /_cat/indices?h=index
GET index/_settings
GET index/_mapping
DELETE /document-index/_doc/id
POST document-index/_delete_by_query?conflicts=proceed
{
"query": {
"match_all": {}
}
}
GET /_analyze
{
"analyzer" : "standard",
"text" : "Hello, from Elastic Search."
}Interacting with Spark
# via package
--packages org.elasticsearch:elasticsearch-hadoop:7.10.1
# or via pip
!pip install elasticsearch-hadoop
df = spark.read
.format("org.elasticsearch.spark.sql")
.option("es.nodes","http://host:9200")
.option("es.read.metadata", "true")
.option("es.read.field.include", "text,user")
.load("index/type")
df.write
.format("org.elasticsearch.spark.sql")
.option("es.nodes","http://localhost:9200")
.option("es.write.operation", "upsert")
.save("index/type")Elasticsearch Admin tools
Elasticsearch Customization with Plugins
Elasticsearch has an interface-based plugin architecture that allows to extend and customize ES functionality. Plugins are generally packaged artifacts (jar, zip, rpm) files kept in a specific location. We can use elasticsearch-plugin command line tool to install, list, and remove plugins. Some common plugin categories are:
API Extension Plugin
Snapshot Plugin
Discovery Plugin
Mapper Plugin
Integration Plugin
GET _cat/pluginsCompanies using Elasticsearch
Swiggy, Quora, AutoDesk, Adobe, Walmart, Grab, Tinder, Uber, Visa, Compass, Pearson, Pinterest, Wikimedia, Netflix
Bottlenecks
- Cluster Manager — As the number of node increase beyond 300 system becomes slow, and cluster restart becomes slow
- Shard Allocator
- No Admission Controller for Bad queries — No proactive prevention to bad queries
- Storage cost becomes high for higher retention data
- Direct coupling between plugin and core, no resource segmentation
- Elasticsearch does not allow multi-datacenter installation.
Cloud Offering in AWS
AWS offers OpenSearch service which is a fork of Elasticsearch. There are two offerings in this service — Managed & Serverless. AWS offering has the following advantages:
Enhanced Security
Alerting
Performance Analyzer
SQL Queries Support
Index Management
k-Nearest Neighbour Search
Future works in the pipeline for OpenSearch
- Remote storage
- Smart Caching
- Cross & Full cluster replication
Summary
In a nutshell, ES indexing can be summarized in the following steps
- Sending data to API
- Data is Routed to the Index, Node, and Shard
- Mapping, Normalization, and Analyses
- Persistence to disk
- Data available for Searching
Thanks for reading !!

