Maximizing Model Effectiveness: A Deep Dive into Fine-Tuning with Azure OpenAI

Fine-tuning involves training an existing Large Language Model with example data, resulting in a customized “custom” Large Language Model that has been optimized based on the provided examples.
Azure OpenAI Service allows you to customize our models according to your specific datasets through a process called fine-tuning. This customization enables you to maximize the effectiveness of the service by offering:
- Higher quality results compared to those achievable solely through prompt engineering.
- The capability to train on a larger number of examples than can be accommodated within the model’s maximum request context limit.
- Reduced latency in requests, especially when utilizing smaller models.
If you identify cost as your primary motivator, proceed with caution. Fine-tuning might reduce costs for certain use cases by shortening prompts or allowing you to use a smaller model but there’s a higher upfront cost to training and you’ll have to pay for hosting your own custom model. Refer to the pricing page for more information on Azure OpenAI fine-tuning costs.
If you want to add out of domain knowledge to the model, you should start with retrieval augmented generation (RAG) with features like Azure OpenAI’s on your data or embeddings. Often, this is a cheaper, more adaptable, and potentially more effective option depending on the use case and data.
Here’s an example for Finetune:
A customer wanted to use GPT-3.5-Turbo to turn natural language questions into queries in a specific, non-standard query language. They provided guidance in the prompt (“Always return GQL”) and used RAG to retrieve the database schema. However, the syntax wasn’t always correct and often failed for edge cases. They collected thousands of examples of natural language questions and the equivalent queries for their database, including cases where the model had failed before — and used that data to fine-tune the model. Combining their new fine-tuned model with their engineered prompt and retrieval brought the accuracy of the model outputs up to acceptable standards for use.
When should you use fine-tuning?:
- If the prompt exceeds its limits or becomes too extensive, opting for fine-tuning is recommended.
- When aiming for exceptional performance in specific tasks, fine-tuning ensures the model is finely tuned to excel in those areas.
Common signs you might not be ready for fine-tuning yet:
- Insufficient knowledge from the model or data source.
- Inability to find the right data to serve the model.
Even with an excellent use case, the effectiveness of fine-tuning depends on the quality of the data you can provide. You must be prepared to invest time and effort to make fine-tuning successful. Different models have varying requirements for data volumes, but typically, you’ll need to supply relatively large amounts of carefully curated, high-quality data.
Customize a model with fine-tuning(Azure OpenAI):
The following models support fine-tuning:
- gpt-35-turbo-0613
- gpt-35-turbo-1106
- babbage-002
- davinci-002
Steps:
- Prepare your training and validation data
- Create your training and validation datasets
- Select the base model
- Choose your training data
- Choose your validation data
- Deploy a custom model
Training data files must be formatted as JSONL files, encoded in UTF-8 with a byte-order mark (BOM). The file must be less than 100 MB in size.
Example of Jsonl file:
{
"messages": [
{
"role": "system",
"content": "You are a tech support agent. Your role is to assist users with tech-related inquiries."
},
{
"role": "user",
"content": "How can I transfer files between my phone and laptop?"
},
{
"role": "assistant",
"content": "You can transfer files between your phone and laptop using various methods such as USB cable, Bluetooth, or cloud storage services. Would you like step-by-step instructions for any of these methods?"
}
]
}Continuous fine-tuning:
Once you have created a fine-tuned model you may wish to continue to refine the model over time through further fine-tuning. Continuous fine-tuning is the iterative process of selecting an already fine-tuned model as a base model and fine-tuning it further on new sets of training examples.
Cost:
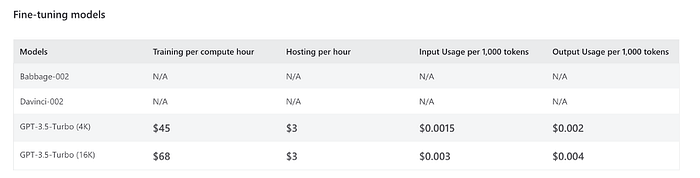
Azure OpenAI fine-tuned models are charged based on three factors:
- Training hours
- Hosting hours
- Inference per 1,000 tokens
It’s important to be aware of the hosting hours cost, especially once a fine-tuned model is deployed. Even when not actively using it, there’s an ongoing hourly expense that needs to be monitored closely.
Let’s take an example:
Assuming that each of my standard search queries comprises 15 input and 300 output tokens, and I conduct 20,000 searches within a month.
Additionally, let’s consider a minimum training duration of 1 hour for each individual PDF.
Consider that I am providing some data to models for fine-tuning and utilizing 1k tokens.
→ Total input cost = Input per 1k tokens * Number of tokens used = $0.003 * (15 * 20000)/1000 = $0.9
→ Total output cost = Output per 1k tokens * Number of tokens used = $0.004 *( 300 * 20000) /1000 = $24 (Considering 300 tokens for output, as the output contains more data in response.)
→ Total hosting cost = Hosting per hour * Hours in a month = $3.00 * 24 * 30 = $2,160
→ Total fine-tuning cost = Fine-tuning per hour * 1 hour for 1 pdf = $68.00 * 100 = $6800 So, the total cost for using 3,00,000 + 6,00,000 = 9,00,000 tokens in one month with Azure GPT-3.5 Turbo would be:
→ Total cost = Total input cost + Total output cost + Total hosting cost + Total fine-tuning cost = $0.9 + $24 + $2,160 + $6800 = $8,984.90
If fine-tuning is not required, then the cost is $2,184.90 per month.

