[Solution] Spark — debugging a slow Application
Follow up blog to fix slow jobs
This blog is a follow-up to this blog where I list reasons for slow Spark Job.
Input / Source
Input Layout
Partitioned data
The right partitioning scheme allows Spark to read only specific data. Also since partitioned columns are not stored along with data it results in fewer data to be scanned as partitioned col is computed on the fly.
|-year=2015
| |-month=JAN
| | |-day=01
| | | |-2015010100.parquet
| | | |-2015010101.parquet
| | | |-2015010102.parquet
............
| | |-day=02
| | | |-2015020100.parquet
| | | |-2015020101.parquet
| | | |-2015020102.parquet
| |-month=FEB
spark.sql.sources.parallelPartitionDiscovery.parallelism
spark.sql.sources.parallelPartitionDiscovery.threshold
Bucketing (SMJ)
Bucketed data results in a shuffle-less join if the number of buckets on both sides of the join is the same or multiple of each other.

Compaction / Split
Merge small files into files of size 128/256 MB based on your need to reduce small file issues with Spark. Similarly, split large files into 128/256 MB sizes to increase parallelism.
Non Splittable file types
- Use Splittable File formats like CSV, Avro, Parquet & ORC
- Use hybrid data file format (Row grouped & Column partitioned) like ORC, or Parquet. Hybrid data file formats give good read and write performance at the same time. Parquet with Spark works like charm.
Multiline
Refrain from using multiline=true while reading data from the source, as this results in reduced parallelism. Also if possible refrain from using complex and deep nested data structures. Write a separate process to flatten these. JSON auto-flattening.
df.write.bucketBy(numBuckets=10, colName='BUCKET_BY_COL').....- Provide Schemas: Avoid inferSchema. Explicitly provide schemas for your data. This allows Spark to avoid the costly process of scanning the entire dataset (1000 rows), resulting in faster schema resolution and improved performance.
- Register as Tables: By registering Spark DataFrames as tables in the metastore, we store the file location and schema information. This enables Spark to leverage metadata for optimizations, reducing the need for repeated scanning and enhancing performance.
- Utilize Delta or similar: Optimized storage layers (like Delta)can take advantage of features like data skipping, file compaction, and optimized file formats, resulting in improved query performance and efficient data storage.
Slow Stage
Uneven partition
If partitions are uneven then we can do a few things to make partitions equal.
Salting
Salting is a way to add random values in the column so that data can be split from the bigger partition into smaller ones.
import random
from pyspark.sql.functions import udf
def rand_part_func():
return random.randint(0, spark.conf.get("spark.sql.shuffle.partitions"))
rand_udf = udf(rand_part_func)
salt_df = spark.range(0, spark.conf.get("spark.sql.shuffle.partitions"))
salted_df = df.withColumn("salted_id", concat("id", lit("_"), lit(rand_udf())))Repartition & Coalesce
Repartition & Coalesce can be used to reduce or increase the count of rows in each partition.
repartition(numPartitions) — Uses RoundRobinPartitioning
repartition(partitionExprs) — Uses HashPartitioner
repartitionByRange(partitionExprs) — Uses range partitioning.
coalesce(numPartitions) — Use only to reduce the number of partitions.Note: Repartition does a full shuffle & coalesce does without shuffle
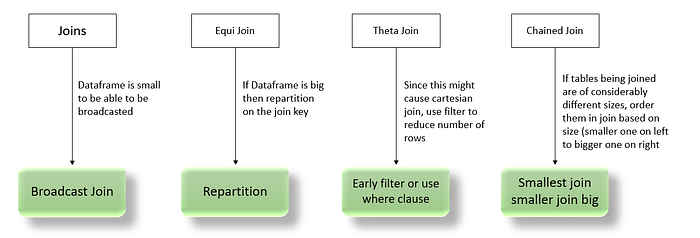
Note: For Broadcast Spark has hard limit of 8GB & while giving broadcast hint we need to use the alias of the given table (if alias created).
Adaptive Query Execution
AQE increases and decreases partitions by dynamically coalescing or splitting the partitions.
spark.sql.adaptive.enabled true
spark.sql.adaptive.skewJoin.enabled true
spark.sql.adaptive.coalescePartitions.enabled true
spark.sql.adaptive.advisoryPartitionSizeInBytes 134217728
spark.sql.adaptive.skewJoin.skewedPartitionFactor
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes
spark.sql.adaptive.advisoryPartitionSizeInBytesNote: Caching the DataFrame just before writing disables AQE for the transformations that occur in our DataFrame before calling cache().
Even Partition
Too many partitions — If we have way too many partitions and way fewer data, we will be wasting resources. Also, it takes some time for executors to come up and those delays will be added to the job.
partition_number = df.rdd.getNumPartitions()
data_distribution = df.rdd.glom().map(len).collect()Too few partitions — If we have fewer partitions then each partition will have more data and each executor slot will process more data sequentially hence jobs will be slow. We can increase the number of partitions by reducing the value setting the maxPartitionBytes.
spark.sql.files.maxPartitionBytes
spark.sql.files.minPartitionNum
spark.sql.shuffle.partitionsHigh Task concurrency — To reduce GC overheads due to the large number of cores with the executor/driver we need to decrease the number of cores. In general, the number of cores can be experimented with in the range of 3–5 for executors with memory in the range of 20–40G.
spark.executor.cores
spark.driver.coresSince we want to maximize task parallelism we also need to increase and decrease the number of executors by enabling dynamic resource allocation with a lower and upper bound.
spark.shuffle.service.enabled true
spark.dynamicAllocation.shuffleTracking.enabled true
spark.dynamicAllocation.enabled true
spark.dynamicAllocation.initialExecutors 100
spark.dynamicAllocation.minExecutors 70
spark.dynamicAllocation.maxExecutors 500
spark.dynamicAllocation.executorIdleTimeoutSlow transformation — Avoid using complex transformation using regex. Stick to native functions in Spark.
Predicate is not pushed — Ensure predicate push-down is enabled in Spark as well as Hive. Also, ensure that in your queries partitioned predicates are used in the where clause. Also, use file formats that support vectorization and predicate push-down and column pruning. The parquet file format supports both.
UDFs — Python Avoid unnecessary UDFs & UDAFs. Use native Spark functions. If needed and possible build UDFs & UDAFs in Scala and build Jars and ship them with Spark binaries.
Slow Executor
Slow executors can be due to GC, JVM conf, or Serialization. We can set specific values for certain fields.
Java Options:
spark.driver.extraJavaOptions
spark.executor.extraJavaOptions
-xx:+UseG1GC(if the memory size is less than 32G.)
xx:+UseCompressedOopsSerializers:
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.sql.execution.arrow.enabled true
Other configurations:
spark.rdd.compress true
spark.io.compression.codec zstd
spark.io.compression.zstd.level 2
Big DAG
We can break a large DAG by Checkpoint.
df = df.filter(FILTER_CONDITION).checkpoint()
df = df.join(df1, on = ['COL_NAME'], how='inner')
df.explain()Slow Cluster
Scheduling delay
While using K8s in batch mode look for schedulers that are fast and support queuing. Use schedulers like Volcano or YuniKorn.
Resource Contention
Use queuing YARN & YuniKorn queue to allow a Fair share of cluster resources between multiple jobs in muti-tenant clusters.
spark.yarn.queue
Resource deadlock between Jobs/apps
Spark allows us to configure resources between jobs and stages in an application. We can use fair scheduling.
spark.scheduler.mode FAIR
Work duplication:
df
Spark’s lazy evaluation sometimes causes the same work to be done twice, if we are not handling it properly. Let us say we have a data frame df and we do select certain records based on the filter and create two different data frames. We apply certain transformations (diff in each data frame) and then merge/union them.
df = df_eu.join(df_lac, how="inner", on="value")
df_1 = df.filter(filter_condition_1)
df_2 = df.filter(filter_condition_2)
## Add a new col aftre performing some transformation
df_1 = df_1.withColumn("new_col", transform_1)
df_2 = df_2.withColumn("new_col", transform_2)
## Union the two data frames
df_1.union(df_2).count()In the above example, we will notice that the join happened twice. To speed up this we can call a cache to persist the joined data frame in memory. So optimizer uses the shortcut to fetch the data instead of computing it from the source.
If we control the 5 S of spark, we can get the maximum out of Spark Jobs
Shuffle
Skew
Spill
Storage
Serialization
Happy Tuning !!

