Unlocking insights from the South African Political Party manifestos : A project using topic modelling concepts and Shiny using R
2024 is a significant year for elections, and South Africa will be holding theirs on May 29. As a passion project, I decided to analyse the political party manifestos to understand the topics they address. With about 70 parties contesting this year’s election, reading through all their manifestos is impractical. Hence, I opted for a topic modelling project using Latent Dirichlet Allocation (LDA) and visualised the analysis through an R Shiny app. I am hoping that the analysis could assist in helping one make a decision on who to vote for or at least intrigue one enough to read their manifesto further.
In this article, we’ll walk through the step-by-step process of using R to analyse political manifestos, visualise key topics with LDA, and interpret the results.
Understanding Latent Dirichlet Allocation (LDA)
Before diving into the code, let’s briefly understand LDA. LDA is a technique used to uncover latent topics from a collection of documents. It assumes that each document can be represented as a distribution over topics and each topic as a distribution over words. By analysing these distributions, we can identify the underlying topics within the documents.
Exploring the R Code
I started off by collecting the pdf versions of each of the polictical party manifestos. I stored and sorted them into a folder and then begin using R for the rest of the analysis.
Just a note for this analysis I only managed to find 15 manifestos and the Patriotic Alliance manifesto was a difficult to read format for R and hence had to use Azure’s Document Reading capabilities — I wrote an article about that here
Let’s break down the R code:
- Setting up the Environment: The code starts by setting up the necessary packages and dependencies required for the analysis.
# Function to check if a package is installed, install it if not, and load it
install_and_load <- function(package_name) {
if (!require(package_name, character.only = TRUE)) {
install.packages(package_name, dependencies = TRUE)
library(package_name, character.only = TRUE)
}
}
# List of required packages
required_packages <- c(
"shiny", "bslib", "tm", "pdftools",
"topicmodels", "LDAvis", "wordcloud", "ggplot2",
"tidyverse", "tidytext", "gridExtra", "jsonlite","scales",
"rprojroot"
)
# Install and load required packages
sapply(required_packages, install_and_load)2. Loading Manifestos: Manifestos from various political parties are loaded into the environment for analysis.
3. Creating a Corpus: The createCorpus function is used to preprocess the text from the manifestos, removing punctuation, numbers, and stopwords.
# Function to create and preprocess a corpus from a PDF or JSON file
createCorpus <- function(pdfFilePath) {
text <- if (grepl(".json", pdfFilePath)) {
json_data <- fromJSON(pdfFilePath)
json_data$analyzeResult$content
} else {
pdf_text(pdfFilePath)
}
corpus <- Corpus(VectorSource(text))
corpus <- tm_map(corpus, content_transformer(tolower))
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeNumbers)
corpus <- tm_map(corpus, removeWords, stopwords("en"))
corpus <- tm_map(corpus, stripWhitespace)
corpus <- tm_filter(corpus, function(x) length(unlist(strsplit(as.character(x), " "))) > 0)
corpus <- tm_map(corpus, content_transformer(gsub), pattern = "[\\*•\\*●*\\*▶*\\*–*\\*▪*]", replacement = "")
corpus <- tm_map(corpus, content_transformer(gsub), pattern = "^\\d+\\.\\s*", replacement = "")
return(corpus)
}4. Word Cloud Generation: The createWordCloud function generates a word cloud visualisation based on the frequency of words in the manifestos.
createWordCloud <- function(corpus, numWords, number_of_colors, color_vector) {
group_size <- numWords / number_of_colors
tdm <- TermDocumentMatrix(corpus)
m <- as.matrix(tdm)
word_freqs <- sort(rowSums(m), decreasing = TRUE)
df_word_freqs <- data.frame(word = names(word_freqs), freq = word_freqs)
df_word_freqs <- df_word_freqs %>%
arrange(desc(freq)) %>%
mutate(rank = row_number(), color_group = ((rank - 1) %/% group_size) + 1)
sa_colors <- color_vector
df_word_freqs$color <- sa_colors[((df_word_freqs$color_group - 1) %% length(sa_colors)) + 1]
wordcloud(words = df_word_freqs$word,
freq = df_word_freqs$freq,
scale = c(4, 0.8),
min.freq = 5,
max.words = numWords,
random.order = FALSE,
rot.per = 0.35,
colors = df_word_freqs$color,
ordered.colors = TRUE, vfont = c("serif", "plain"), font = 3)
}5. LDA Model Creation: The createLDAmodel function is responsible for creating an LDA model from the corpus of text. It identifies the underlying topics within the manifestos.
# Function to create an LDA model
createLDAmodel <- function(corpus, numTopics = 5) {
dtm <- DocumentTermMatrix(corpus)
sparse_dtm <- removeSparseTerms(dtm, 0.999)
empty_docs <- which(rowSums(as.matrix(sparse_dtm)) == 0)
filtered_dtm <- if (is_named_integer_0(empty_docs)) sparse_dtm else sparse_dtm[-empty_docs, ]
lda_model <- LDA(filtered_dtm, k = numTopics)
return(lda_model)
}6. LDA Visualisation: The createLDAVisualization function generates an interactive visualisation using the LDAvis package, allowing users to explore the topics identified by the LDA model.
# Function to run LDA and visualize the model
createLDAVisualization <- function(corpus, numTopics = 5, termsPerTopic = 10) {
dtm <- DocumentTermMatrix(corpus)
sparse_dtm <- removeSparseTerms(dtm, 0.999)
empty_docs <- which(rowSums(as.matrix(sparse_dtm)) == 0)
filtered_dtm <- if (is_named_integer_0(empty_docs)) sparse_dtm else sparse_dtm[-empty_docs, ]
lda_model <- LDA(filtered_dtm, k = numTopics)
topics <- terms(lda_model, termsPerTopic)
posterior_results <- posterior(lda_model)
theta <- posterior_results$topics
phi <- posterior_results$terms
doc_lengths <- rowSums(as.matrix(filtered_dtm))
vocab <- colnames(as.matrix(filtered_dtm))
term_frequency <- colSums(as.matrix(filtered_dtm))
if (length(doc_lengths) == nrow(theta)) {
LDAvis::createJSON(
phi = phi,
theta = theta,
doc.length = doc_lengths,
vocab = vocab,
term.frequency = term_frequency,
R = termsPerTopic
)
} else {
print("Mismatch in the number of documents")
print(paste("Doc lengths:", length(doc_lengths)))
print(paste("Theta rows:", nrow(theta)))
}
}7. Top Terms per Topic: Finally, the extract_top_terms function extracts the top terms associated with each topic, which are then visualized in a bar plot.
# Extract top terms from each topic
extract_top_terms <- function(phi, vocab, n = 10) {
top_terms <- apply(phi, 2, function(topic) {
top_indices <- order(topic, decreasing = TRUE)[1:n]
data.frame(term = vocab[top_indices], probability = topic[top_indices])
})
top_terms <- do.call(rbind, lapply(1:length(top_terms), function(i) {
top_terms[[i]]$topic <- i
top_terms[[i]]
}))
return(top_terms)
}Running the Analysis
To explore the full code and run the analysis yourself, you can access the GitHub repository. Additionally, if you’re new to R or looking for a user-friendly interface, tools like Posit Cloud make it easier to write and execute R code, even for beginners. The Posit Cloud repository links directly to the Git repository of the project.
Interpreting the output
Once the code is executed, a Shiny app will be generated, providing an interactive way to analyse political manifestos using text mining and text modelling techniques. Users can select a political party, specify the number of words for the word cloud, and adjust the number of terms and topics for the LDA model. The app then visualises the key themes and topics within the selected manifesto, helping users gain insights into political discourse.
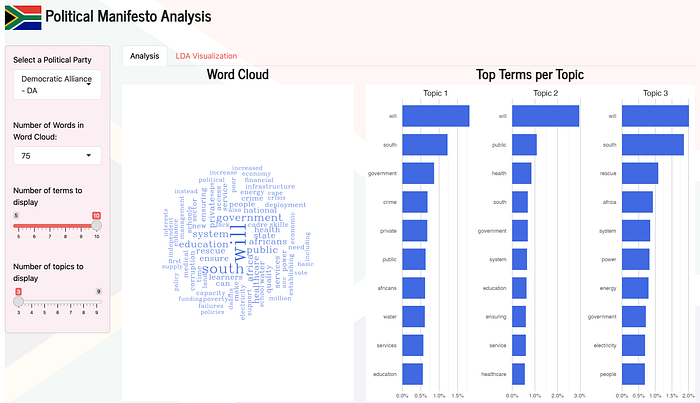
- Word Cloud: Provides a visual summary of the most common words used across all manifestos. The size of each word corresponds to its frequency in the text.
- Top Terms per Topic: Displays the most relevant terms for each topic. The x-axis represents the probability of each term within the topic, allowing users to identify key terms.
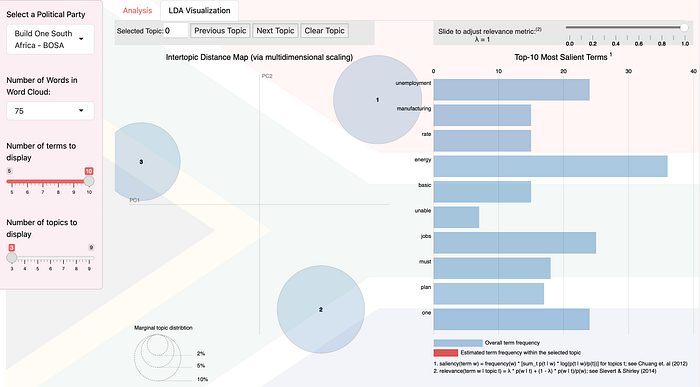
- LDA Visualisation: Offers an intuitive way to explore the relationships between topics and words. Each topic is represented as a circle, and the size of the circle corresponds to the prevalence of the topic in the corpus. The distance between circles indicates the similarity between topics.
Analysing political manifestos can reveal valuable insights into the priorities and agendas of political parties. By leveraging techniques like Latent Dirichlet Allocation (LDA) and interactive visualisations in R, we can uncover hidden themes and topics within the text. This analysis helps us understand the focus areas of different parties, aiding voters and analysts in making informed decisions.
Insights from Specific Selection
For my analysis, I focused on identifying the top three topics per manifesto, highlighting the top ten words for each topic, and setting the word cloud to display the top fifty words used.
Note the names and acronyms of political party manifestos included :
African National Congress — ANC
Democratic Alliance — DA
Economic Freedom Fighters — EFF
Freedom Front Plus — FF Plus
United Democratic Movement — UDM
Al Jama-Ah
Build One South Africa — BOSA
RISE Mzansi — RISE
African Transformation Movement — ATM
ActionSA
Inkatha Freedom Party — IFP
GOOD Party — GOOD
African Christian Democratic Party — ACDP
Patriotic Alliance — PA
People’s Revolutionary Movement — PRM
Here are my findings:
Common Themes
- The word “will” appeared in almost all word clouds, except for ATM (which didn’t have “will” or “shall”) and PRM (which used “shall” instead). This suggests that many parties either have the “will” to accomplish something or claim they “will” do something once elected.
- Topics like healthcare, infrastructure, education, jobs, water, and energy/electricity supply were common across many parties, reflecting concerns about these areas’ deterioration under the current governing party.
Unique Findings
- UDM was the only party where the word “woman” appeared in the word cloud. This is notable given South Africa’s issues with women’s safety.
- Several parties (BOSA, ActionSA, EFF) included topics related to security and police, which could indirectly address women’s safety.
- The DA, FF Plus, and PA emphasised themes of rescuing, restoring, or turning around the country.
- Al Jama-ah had a topic focused on the youth.
- The word “corruption” appeared in the word clouds for UDM and the DA, highlighting a major issue in South Africa’s recent history.
Specific Party Insights:
- Immigration and foreign nationals were topics for RISE, PA, and PRM.
- The ACDP mentioned the agricultural sector, with “farmers” appearing in their word cloud. They also referenced COVID-19, which might be related to the pandemic’s impact on the country.
- The GOOD party had a topic on climate change and was the only party to mention “Apartheid” in their word cloud. This is surprising, given the ANC’s frequent references to Apartheid in their campaigns but didn’t even appear on the ANC’s word cloud.
- The IFP emphasised “trust” across all three topics, centring their campaign around “doing it for Shenge” and Mangosuthu Buthelezi.
- FF Plus mentioned the ANC in their manifesto enough for it to appear in their word cloud.
Conclusion
The work that has gone into developing the Shiny app and performing the topic modelling analysis on South African political party manifestos has been extensive and detailed. By using Latent Dirichlet Allocation (LDA) and interactive visualisations in R, I have created a tool that uncovers hidden themes and key topics within the text of each manifesto. This tool allows users to gain a deeper understanding of the priorities and agendas of various political parties, providing valuable insights that can inform voter decisions.
The Shiny app is designed to be user-friendly and interactive, offering several features that benefit users:
- Word Clouds: Visual summaries of the most frequently used words in the manifestos, providing an at-a-glance view of key themes.
- Top Terms per Topic: Detailed displays of the most relevant terms for each topic, helping users identify important issues.
- LDA Visualisation: An intuitive exploration of the relationships between topics and words, showing the prevalence and similarity of different topics.
Through this analysis, users can better understand the focus areas of different parties, aiding them in making more informed decisions about who to vote for. The insights gained can highlight the priorities of each party, such as healthcare, education, jobs, and security, as well as unique focuses like women’s safety and youth issues.
Future Recommendations
To enhance the tool further, several recommendations are suggested:
1. Comparison Feature: Add a comparison page where users can select and compare two or three parties side by side.
2. Accessibility: Publish the app to an easily accessible web link for non-technical R users.
3. Summarisation: Add a summarisation page where each manifesto is condensed into a few sentences for easier interpretation, possibly using an integration with a GPT API.
4. Interactivity: Enhance the interactivity of the word cloud and topic bar graphs.
5. Lemmatisation: Implement lemmatisation to reduce words to their base forms.
6. Frequency Limit: Set a frequency limit on the words included in the word cloud to filter out less significant words.
7. Keyword Search Feature: Add a feature where users can select a keyword like “woman” or “youth,” and the tool returns the party or parties that mention that topic.
I would love to hear your feedback on how to improve the tool. Your insights and suggestions will be invaluable in refining the app to better serve the needs of voters and analysts alike. This project aims to provide a clear, accessible way to understand political party manifestos and make informed voting decisions. Your feedback will help ensure the tool is as effective and user-friendly as possible.

